1️⃣ 컨트롤러
다수 브로커 중 한대가 컨트롤러의 역할을 해서 헬스체크하고 비정상이면 빠르게 클러스터에서 빼내기.
2️⃣ 컨슈머 오프셋 저장
어느 레코드까지 가져갔는지 확인하려고 오프셋 커밋. _consumer_offsets 토픽에 저장
이건 언제보냐? 장애 났을 때 어디까지 토픽 저장됐는 지 확인할 때 본다.
3️⃣ 그룹 코디네이터
파티션을 컨슈머와 매칭되도록 분배.
컨슈머가 보통 1:1 처리 중인데 만약 컨슈머가 장애나서 빠지면 파티션을 정상 컨슈머로 할당해서 한 컨슈머가 여러 파티션 처리하게 우선 리밸런스함.
4️⃣ 데이터의 저장
카프카를 실행할 때 config/server.properties의 log.dir 옵션에 정의한 디렉토리에 데이터를 저장하는데 토픽 이름과 파티션 번호의 조합으로 하위 디렉토리를 생성하여 데이터를 저장.

예를 들어, 위의 예시에서는 config/server.properties의 log.dir 옵션에 정의한 디렉토리가 /tmp/kafka-logs라고 할 때, hello.kafka 토픽의 0번 파티션에 존재하는 데이터 확인 가능. log에는 메시지와 메타데이터 저장.
index는 메시지 오프셋을 인덱싱한 정보 담은 파일, timeindex 파일에는 메시지에 포함된 timestamp 값을 기준으로 인덱싱한 정보가 담겨 있음.
5️⃣ 데이터 삭제
카프카는 컨슈머가 데이터 가져가도 토픽의 데이터가 삭제되지 않는데, 브로커만이 데이터를 삭제할 수 있음.
데이터 삭제는 파일 단위로 이뤄져서 이 단위를 로그 세그먼트라 한다.
이 세그먼트에는 다수의 데이터가 들어 있어서 일반적인 데이터베이스처럼 특정 데이터만 선별 삭제는 불가하다.
로그와 세그먼트
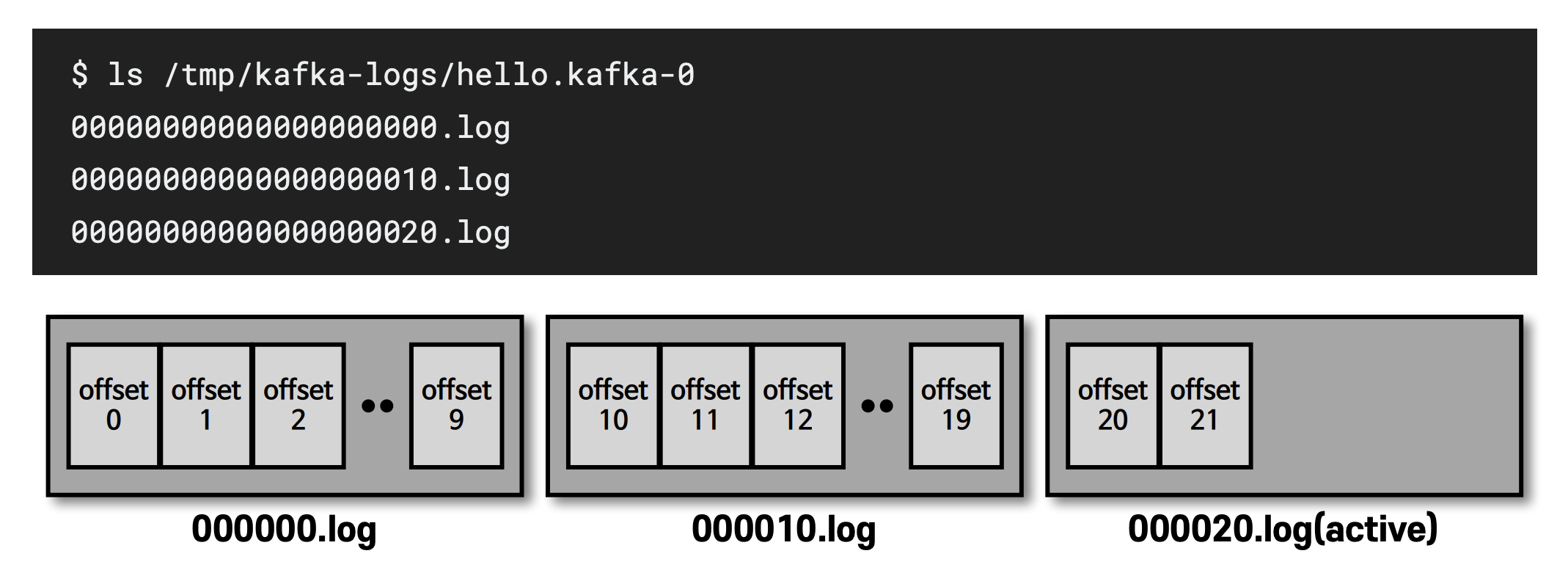
- log.segments.bytes : 바이트 단위의 최대 세그먼트 크기 지정 (기본값 1GB)
- log.roll.ms : 세그먼트가 신규 생성된 이후 다음 파일로 넘어가는 주기 (기본값 7일)
- 가장 마지막 세그먼트 (쓰기 일어나고 있는파일) 를 액티브 세그먼트라고함. 액티브 세그먼트는 삭제 못하고 액티브 세그먼트가 아닌 애들은 retention 옵션에 따라 삭제 대상으로 지정.
세그먼트의 삭제(cleanup.policy=delete)
- retention.ms : 세그먼트 보유 최대기간 (3일 유지가 일반적. 워킹데이동안은 언제든 데이터 접근 가능하지만 주말에는 직접적으로 대응 어려울 때가 많아서 주말에 접근 어려워도 월요일에 대응 가능하려면 3일이 적당함.)
- retention.bytes : 파티션당 로그 적재 바이트값.
- log.retention.check.interval.ms: 브로커가 세그먼트가 삭제영역이 들어왔는지 확인하는 간격 (5분이 기본값.)
토픽의 압축(cleanup.policy=compact)

- 압축 : 키 값을 기준으로 삭제하는 방식을 의미함.
- 메시지 키 단위로 가장 최근 메시지키 단위만(액티브 키 단위만) 삭제하기
테일/헤드 영역, 클린/더티로그

- 테일 영역: 압축정책에 의해 압축이 완료된 레코드들. 클린로그라고도 부름. 중복메시지 키 없음.
- 헤드 영역: 압축정책이 되기 전. 더티 로그라고도함.
- min.cleanable.dirty.ratio : 액티브 세그먼트를 제외한 세그먼트에 남아 있는 테일 영역의 레코드 개수와 헤드 영역의 레코드 개수의 비율. 0.5로 설정하면 테일 영역 레코드개수와 헤드 영역 개수 같고, 0.9와 같이 크게 설정하면 한번 압축시 많은 데이터가 줄어듦. 그러나 0.9 비율이 될 때까지 용량을 차지해서 용량효율은 안 좋음. 0.1과 같이 작게 설정하면 압축이 자주 일어나서 가장 최신 데이터만 유지할 수 있으나 브로커에 부담.

6️⃣ 데이터 복제
- 데이터 복제를 함으로써 브로커 일부 장애 발생하더라도 데이터 유실 방지

- 파티션 단위로 복제
- 토픽을 생성할 때 파티션 복제 개수도 같이 설정되는데 직접 옵션 선택하지 않으면 브로커에 설정된 옵션 따라감. 복제 개수 최솟값 1(복제없다는 뜻). 최댓값은 브로커 개수만큼.
- 리더가 프로듀서, 컨슈머와 직접 통신. 복제 데이터를 가지고 있는 파티션은 팔로워.
- 파티션 복제로 인해 저장용량 증가한다는 단점은 있음. 그래도 가용성을 위해 2이상은 정하는게 중요.
장애 발생시
팔로워 파티션 중 하나가 리더 파티션으로 승급.
ISR (In-Sync-Replicas)
리더 파티션과 팔로워 파티션이 모두 싱크가 된 상태

즉, 오프셋 동일한 상태면 뭐 문제없음

그런데, 리더 파티션의 데이터를 아직 팔로워 파티션이 모두 복제하지 못한 상태가 있을 수도 있음. 이러면 데이터가 유실 될 수 있는데
- unclean.leader.election.enable : 해당 값이 true 이면 유실을 감수하겠다는 뜻. 복제가 안된 팔로워 파티션을 바로 리더로 승급. false이면 유실을 감수하지 않고, 원래 브로커가 복구될 때까지 그냥 중단하겠다는 뜻.
이 포스팅은 모두 인프런의 [아파치 카프카 애플리케이션 프로그래밍] 개념부터 컨슈머, 프로듀서, 커넥트, 스트림즈까지!를 듣고 제가 다시 볼 내용들을 정리한 포스팅입니다.

'DevOps > Kafka' 카테고리의 다른 글
| [카프카 프로그래밍] 파티션 개수와 컨슈머 개수의 처리량 (0) | 2024.06.27 |
|---|---|
| [카프카 프로그래밍] 토픽과 파티션 (0) | 2024.06.27 |
| [카프카 프로그래밍] 카프카 생태계와 브로커, 주키퍼 (0) | 2024.06.22 |
| [카프카 프로그래밍] 아파치 카프카가 데이터 파이프라인으로 적합한 4가지 이유 (2) | 2024.06.16 |
| [카프카 프로그래밍] 아파치 카프카의 탄생과 기본 구조 (0) | 2024.06.16 |